python爬取软件、python爬取软件里面的信息
尤其是windows用户同步讲解视频和获取python源码的途径如下本案例的同步讲解视频和案例的python爬虫源码及结果数据已打包好,并上传至微信公众号quot老男孩的平凡之路quot,后台回复quot爬百度quot获取,点链接直达另,20221124更新,已将这个爬虫封装成exe软件,感兴趣的朋友可以关注公众号获取更多资源;Python网络爬虫可以用于各种应用场景,如数据采集信息抓取舆情监控搜索引擎优化等通过编写Python程序,可以模拟人类在浏览器中访问网页的行为,自动抓取网页上的数据Python网络爬虫具有灵活性和可扩展性,可以根据需求自定义采集规则,获取所需的数据同时,Python拥有丰富的第三方库和工具,如。
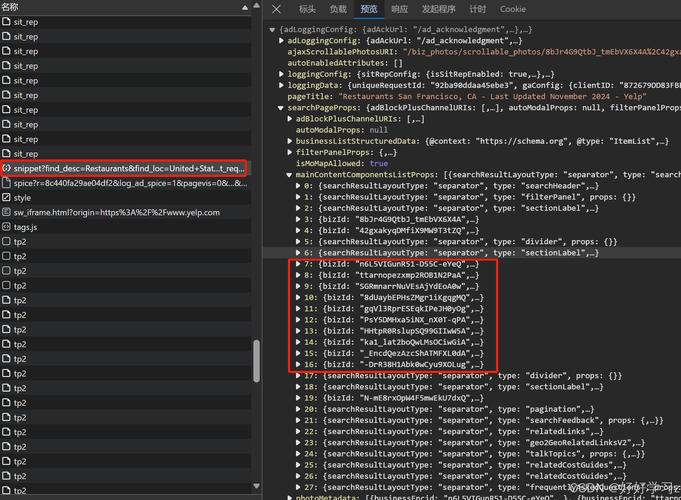
要使用Python爬取Bilibili视频,首先确保安装了ffmpegffmpeg用于合成音频与视频,因为Bilibili的音频和视频数据分开,合成后才能得到所需的视频安装 ffmpeg 软件并配置环境变量可从xyz20获取运行代码,在新建的爬虫文件夹中会生成一个视频注意,源代码中的url变量需替换为所需下载的网址若下载;可以直接启动“乐刻APP”再来抓一波LefitAppiumpy LefitMitmAddonpy 接下来就是见证奇迹的时刻了 可以看到左侧的手机已经自动跑起来了 所有流过的数据都尽在掌握这个方案的适应能力非常强,不怕各种反爬虫机制 但是如果要去爬取淘宝携程等海量数据时,肯定也是力不从心。
为了提高数据采集效率,使用如Autojs或Appium等自动化工具创建自动滑屏脚本,在抖音应用中运行该脚本来实现数据的自动采集注意事项 在进行数据抓取时,务必遵守相关法律法规,尊重抖音平台的使用协议和隐私政策 合理使用爬虫技术,避免对抖音服务器造成过大压力或损害 如遇到技术难题,可以通过;在数据处理工作中,常见需要获取网站数据的场景面对网站的反爬机制,利用Playwright等自动化测试工具,通过模拟浏览器操作,从而获取数据成为解决之道Playwright,微软于2020年初开源的自动化测试工具,功能与Selenium类似,可驱动浏览器执行自动化任务,实现高效便捷的数据爬取Playwright的特点在于支持多种。
python爬取poi
Python提供了高效的高级数据结构,还能简单有效地面向对象编程而如果你是零基础想要自学Python的话,那么就建议你进行专业系统的视频课程学习为帮助广大Python学习爱好者提升,精选到了几套专业优质的Python自学视频课程,学习就可以掌握Python编程技巧以及第三方库使用方法~python爬虫框架讲解1Scrapy Scrapy。
环境说明python 371, centos 74, pip 1001 部署若安装失败,重试直至完成导入douyin模块若报错,检查douyin模块是否已成功安装爬取抖音小视频和音乐几分钟后,视频配乐存储为mp3格式,抖音视频为mp4文件,结果存储清晰py脚本目标包含爬取热门话题和音乐下的视频,下载视频及其配。
本文介绍使用Python和Selenium库实现对B站视频的爬取特别是针对需要登录后才能获取的清晰度较高的视频通过登录B站获取cookie,之后在浏览器中注入该cookie,实现已登录状态下的视频爬取准备工作中,需安装Python 37版本及相应编辑器确保具备jsonosretimerequestsBeautifulSoup库另外,需。
以下是常见Python爬虫框架1ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中它是很强大的爬虫框架,可以满足简单的页面爬取,比如可以明确获知url pattern的情况用这个框架可以轻松爬下来如亚马逊商品信息之类的。
数据爬取软件推荐ScrapyScrapy是一个强大的Python库,用于从网站上抓取数据其优势如下1 高效性Scrapy采用异步IO处理,能够快速地从网站爬取大量数据这对于需要从多个网页中提取信息的情况特别有用2灵活性Scrapy提供了丰富的API接口,用户可以根据需求定制自己的爬虫,无论是简单的数据提。
python爬取软件里面的信息
3 微信小程序爬虫 4 手机APP爬虫 爬取超级猩猩的课表,该平台仅提供了微信小程序这一个途径,前面两种针对html网页的爬取方式都不再适用采用抓包分析是我们制定方案的第一步我用的Mac电脑,fiddler只有一个简化版,所以另找了Charles这个类似的软件启动Charles的代理,在手机WIFI中设置好对应的。
1Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中 2pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储。
Mercury 是一个开源自动化解析工具,基于JavaScript编写,提供Chrome扩展支持,能够智能解析页面内容,如自动提取文章标题正文发布时间等,通过命令行操作,速度快且开源在Python开发者中广受欢迎的是 Scrapy,一个强大的爬虫框架,性能卓越可配置性强,拥有活跃开发者社区和丰富插件,几乎能够实现任何。
python软件为什么叫爬虫软件爬虫通常指的是网络爬虫,就是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本所以Python被很多人称为爬虫python软件的特点1相比于其他编程语言,Python爬取网页文档的接口更简洁2Python的urllib2包提供了完整的访问网页文档的API3python中有优秀的第。
至此,我们就完成了利用python网络爬虫来获取网站数据总的来说,整个过程非常简单,python内置了许多网络爬虫包和框架scrapy等,可以快速获取网站数据,非常适合初学者学习和掌握,只要你有一定的爬虫基础,熟悉一下上面的流程和代码,很快就能掌握的,当然,你也可以使用现成的爬虫软件,像八爪鱼后羿。
你get 是一款基于 Python 3 的下载工具,主要用于从互联网获取多媒体文件在 GitHub 上,你get 的官方项目链接和官方网站提供了详细的使用文档和帮助信息在安装你get 之前,请确保你的系统已正确安装 Python 并将其添加至系统 PATH 环境变量中接下来,只需遵循以下步骤即可完成安装步骤一。
要在Python中使用Scrapy框架爬取西刺代理IP,您可以按照以下步骤操作一环境搭建 确保已安装Python 使用pip安装Scrapy框架pip install scrapy二创建Scrapy项目1 创建项目在命令行中进入您希望存放Scrapy项目的工作区间,运行scrapy startproject xici_proxy2 定义项目结构在创建的项目文件夹。
相关文章
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~